Compositional graphs
One of the main promises of Artificial Intelligence (AI) is to create models that generalize to new datapoints, as well as adapt easily to new tasks (meta-learning). While current state-of-the-art end-to-end deep learning (DL) systems can, for most problems, generalize to new datapoints, they lack generalizability in the presence of distribution shifts of inputs/outputs, covariates and hidden variables, thus making them unable to adapt to new related tasks. Such distribution shifts happen often due to changes in the environment (e.g. training a robot to navigate on the streets of London and then deploying it in New York City), hardware upgrades (e.g. scanners in the hospital are upgraded, necessitating re-training of medical AI models) or the population studied (different countries have different disease risks, requiring re-calibration of medical diagnosis models). In addition, the monolithic architecture of many deep learning models makes it unsuitable for modelling causal relationships between variables, or making predictions that adhere to a certain causal structure.
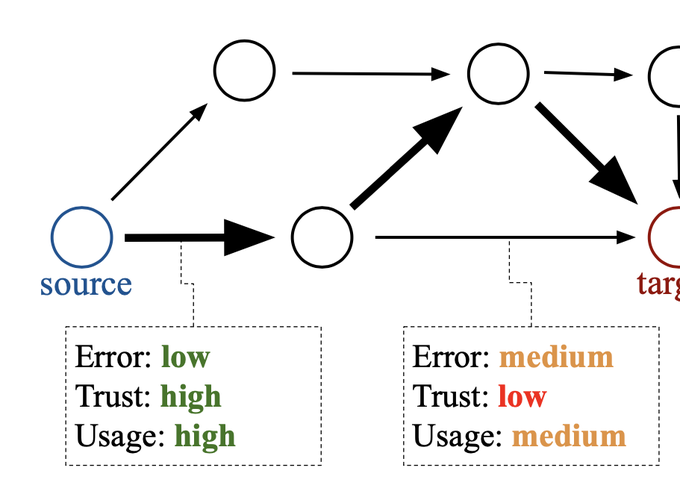
To deal with these problem, we have been working on building a compositional graphs of ML models that is both compositional and modular. This is implemented as a directed graph G(V,E), where each vertex V is a dataset and each directed edge (v1 -> v2) is an ML model that takes input v1 and outputs v2. An example of such a graph is shown below for medical imaging.

It integrates a variety of medical data such as T1 and T2 MRIs, PET scans, segmentation masks, medical reports, cognitive tests, genetics and diagnoses. Each directed path from a source node to a target node becomes an ML predictor that can be run and finetuned further.

Growing such a graph will be a tremendous challenge, as we will have different datasets (nodes in the graph) for each different hospital, different scanner type, scanning modality, etc … We therefore plan to crowdsource the building of the graph on a web platform. Users will be able to commit (just like git commit) new nodes (datasets) or edges (ML models) to the graph and collectively grow such a computational graph. For example, for a new dataset, the user will be able to commit it as a new node, and then commit another ML model that connects the node to one of the existing nodes in the graph. If each edge (ML model) gets assigned a weight (erorr of the model), the user will then be able to find the shortest path to a target node, and thus find the optimal predictor that exists in the graph.

I’m a student and I’d like to work on this project
I’m actively looking for strong students to work on this project. Strong programming expertise is required, along with experience in cloud computing, making UIs, experience with PyTorch or similar DL frameworks, and strong understanding of ML.